Searching images based on text using CLIP model
CLIP is an AI model that provides possibilities to work with images and text as the same data structure. CLIP bridges the gap between pictures and words by learning to understand both in a shared language (embeddings). This is actively used in implementing semantic image search based on provided queries.
What is CLIP
A CLIP (Contrastive Language–Image Pre-training) is an AI model that learns to understand and match images with text. CLIP learns to pair each photo with its correct (prepared beforehand) description by studying many examples. It does this by transforming both images and text into embeddings within a common “vector space,” where similar items are placed close to each other, and different items are placed far apart:
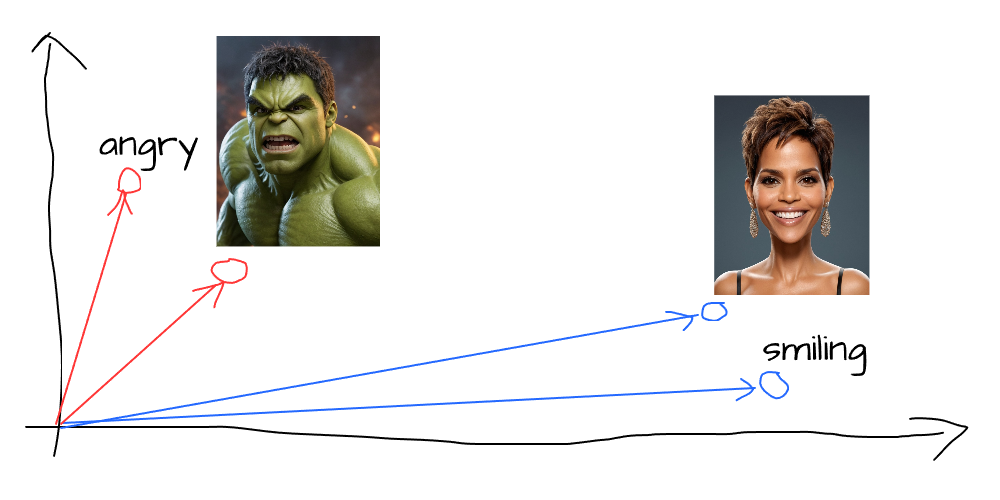
Think of the vector space as a big map. If you have a picture of smiling Halle Berry and the word “smile,” both will end up near each other on this map because they are similar. If you have a picture of an angry Hulk and the word “smile,” they will be far apart because they don’t match.
CLIP uses this map (vector space) to quickly find the best match between images and text, which makes it very powerful for tasks like image search or generating descriptions for pictures.
Installing and running CLIP
To start using (CLIP)[https://github.com/openai/CLIP] let’s first install it. Better use (mini)conda if you don’t want to break your default environment:
conda install --yes -c pytorch torchvision cudatoolkit
pip install ftfy regex tqdm
pip install git+https://github.com/openai/CLIP.gitTo check if that worked, let’s test a short program:
import torch
import clip
from PIL import Image
device = "cuda" if torch.cuda.is_available() else "cpu"
model, preprocess = clip.load("ViT-B/32", device=device)
text = clip.tokenize(['smile', 'angry']).to(device)
text_features = model.encode_text(text)
image = preprocess(Image.open('halle-berry.jpg')).unsqueeze(0).to(device)
image_features = model.encode_image(image)
logits_per_image, logits_per_text = model(image, text)
probs = logits_per_image.softmax(dim=-1).cpu().numpy()
print(probs)[[ 0.99604297 0.00395705 ]]from PIL import Image— we need Pillow image to load images from disk,device =— make sure to use CUDA when possible,clip.tokenize— prepare our text queries -smileandangry,model.encode_text— get text embeddings,model.encode_image— get image embedding,model(image, text)— compare image and text embeddings,logits_per_image— will contain probabilities of all given text queries for this image.
Search images using text query
Suppose we have the following image set:

Instead of searching based on a single text query, let’s do the labeling. We have multiple labels (search queries) and we want to assign those to our images (pick the best label for each image). Since CLIP returns probability for each given text query (from 0 to 1), we can just pick the label with the biggest probability value as the best.
Let’s code that:
import torch
import clip
from PIL import Image
device = "cuda" if torch.cuda.is_available() else "cpu"
model, preprocess = clip.load("ViT-B/32", device=device)
labels = ['Hero', 'Adele', 'Zombie', 'Painting', 'Villain', 'Water'];
text = clip.tokenize(labels).to(device)
text_features = model.encode_text(text)
for i in range(6):
image = preprocess(Image.open(f'{i+1}.jpg')).unsqueeze(0).to(device)
with torch.no_grad():
image_features = model.encode_image(image)
logits_per_image, logits_per_text = model(image, text)
probs = logits_per_image.softmax(dim=-1).cpu().numpy()
print(f'image {i+1}')
for pi, pv in enumerate(probs[0]):
print(' ', labels[pi], ':', pv)image 1
Hero : 0.0011218817
Adele : 0.996808
Zombie : 0.0003685164
...
Villain : 0.033167884
Water : 0.0027887349labels— defines all labels we want to assign to images,text_features— we got label embeddings in this variable now,Image.open(f'{i+1}.jpg')— loads an image given we have1.jpg,2.jpg, etc on disk,probs— list of label (text query) probabilities,enumerate(probs[0])— renders each label with its probability.

As we can see, even the doll that looks like Adele was correctly labeled. The hardest choice was for the painting image, but still, the top probability was picked correctly.
Using the CLIP model to build an image search engine involves creating vectors for both images and text. First, we process our image collection through the CLIP model using model.encode_image() method to get embeddings. Those embeddings should be then saved into a database like Clickhouse. When a user types a text query, convert it into a vector using model.encode_text() and search for the nearest vectors in our DB. That’s it.
Further reading
- Read about text embeddings,
- Find out how image embeddings are generated and used,
- See to do efficient similar vectors search in production.
Edit this article on Github