Image similarity search based on embeddings and sentence_transformers
A vector is a mathematical object that has both a direction and a magnitude, typically represented as an array of numbers. At the very basic level, a vector is just a set of numbers (its coordinates).
In the context of data, vectors can be used to represent various types of information in a numerical format. When we talk about embeddings, we’re referring to the process of transforming complex data, like words or images, into these numerical vectors.
Image embedding, specifically, involves converting an image into a vector that captures important features and patterns within the image. This allows machines to understand and analyze images more effectively, making it easier to perform tasks like image recognition and classification in machine learning.
Similar images = similar image embeddings
Image embedding vectors gravitate towards similar features of images. If we visualize that in 3D (though embeddings have hundreds of dimensions usually), we find that similar images are situated close to each other:
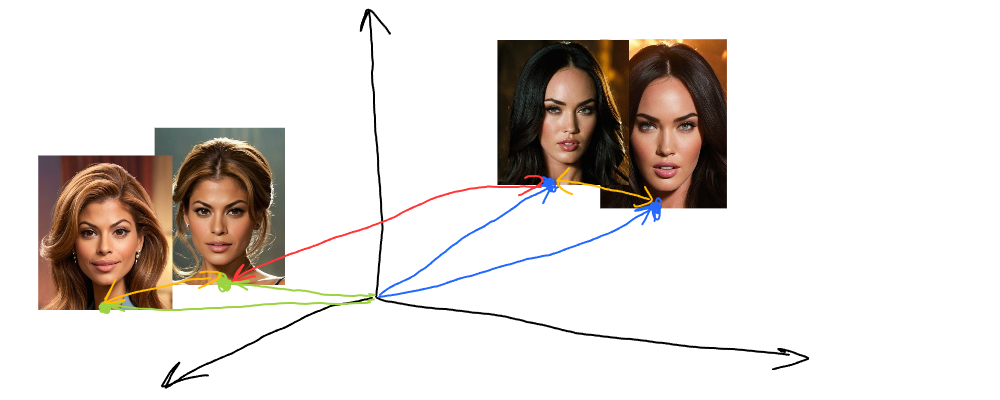
As illustrated, Eva Mendes’s images are close to each other but far from Megan Fox’s. Eva’s image embeddings (vectors) are green, while Megan’s embeddings are blue. Similar images will have vectors that are close to each other (more on vector similarity search). This is the property we’re going to use to find similar images - build embeddings and find the nearest ones.
1. Converting images to vectors (embeddings)
We’re going to use sentence_trasformers lib, which makes it easy to use embedding models. First, let’s install this module:
pip install sentence_transformersTo generate an embedding for an image we only need to pick a model and load an image. We’re going to use clip-ViT-B-32 model which has shared text and image space (which means we can directly compare text with images, but that’s a separate article). Let’s code it now:
from sentence_transformers import SentenceTransformer
from PIL import Image
model = SentenceTransformer("clip-ViT-B-32")
image = Image.open('image.jpg')
vector = model.encode(image)
print(vector)[-2.79104441e-01 2.57993788e-01 -7.66323954e-02 2.35199034e-01
...
6.64310992e-01 -7.79335350e-02 4.23714638e-01 2.20056295e-01]model = SentenceTransformer— creates a new sentence transformer object with a specified model,Image.open— loads given image by path (image.jpg),model.encode(image)— generates and returns vector (image embedding),
Our resulting vector has 512 dimensions (consisting of 512 floating point numbers). Note, that generating an embedding on a CPU might be slower since this is done by an NN model, so consider running on GPU instead.
2. Storing embedding
Now we have to generate vectors for all of our images. We need a storage for that. In our example, we use the ClickHouse database, which has built-in capabilities to work with vectors:
CREATE TABLE embeddings
(
`image` String,
`vector` Array(Float32)
)
ENGINE = MergeTree ORDER BY imageQuery id: 8c76b807-02a2-4157-8d43-f5fbc901ad74
Ok.
0 rows in set. Elapsed: 0.018 sec. embeddings— this table will store images and their embeddings,image— column to store image path,vector— column for embedding, we just useArray(Float32)which is an array of float numbers.
After embeddings are generated, we just insert them into ClickHouse:
INSERT INTO embeddings VALUES('image.jpg', [-2.79104441e-01, ..., 2.20056295e-01])Note, how we pass vector column value, which ClickHouse perfectly understands.
3. Querying similar images based on embeddings
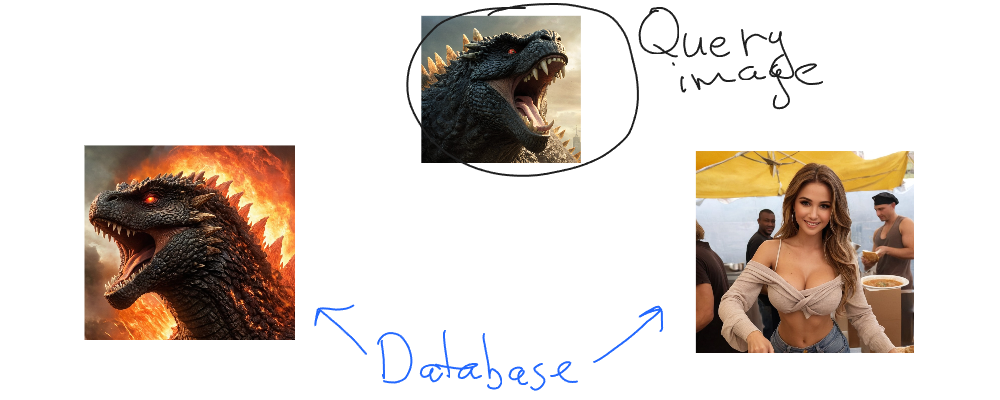
Let’s suppose we have the following image (top one) to find similar to in our database (2 bottom images):
We’ll use L2Distance function to calculate distances between database embeddings and query embedding:
SELECT
image,
L2Distance(vector, [...]) AS distance
FROM embeddings
ORDER BY distance
LIMIT 2┌──image──┬──distance─┐
│ 1.jpg │ 3.895906 │
│ 2.jpg │ 12.46083 │L2Distance(vector, [...])— calculates distances between an embedding in the database and a given one,ORDER BY distance— we want to find the nearest vectors (the ones with the lowest distance metric),LIMIT 2— it’s a good idea to limit results since production databases might have millions…billions of rows.
The first image has the distance metric which is 3 times less than the second one. This means the first image is much closer to the query image than the second one.
Let’s illustrate the result we’ve got:
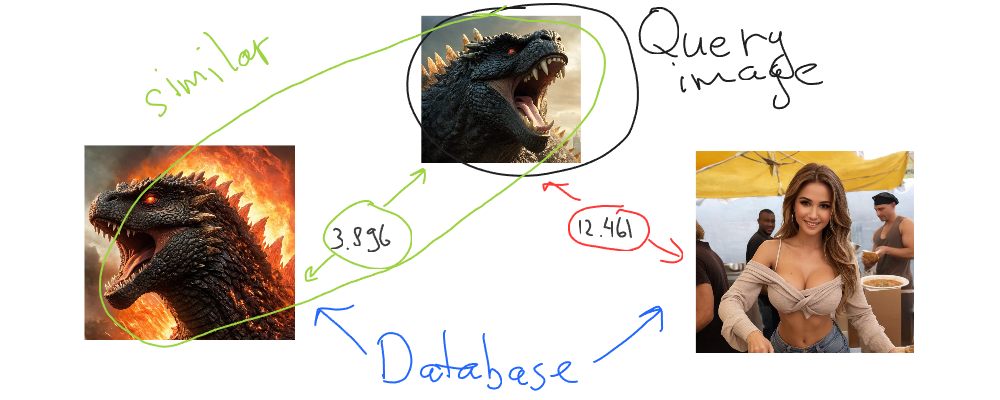
So Godzilla is similar to Godzilla but different from a beautiful girl on the street. Looks good. That’s how we search for similar images.
We could also add some threshold to filter out completely irrelevant images:
SELECT
image,
L2Distance(vector, [...]) AS distance
FROM embeddings
WHERE distance < 5
ORDER BY distance
LIMIT 2Play with the threshold (5 in the example above) in your situation to pick the right figure and not lose valuable results.
Further reading
Published 2 years ago in #machinelearning about #embeddings, #sentence_transformers, #clip, #vector search, #python and #clickhouse by Denys GolotiukEdit this article on Github