Efficient vector similarity search with Annoy library based on ANN
What is vector similarity search
Finding two (or more) similar vectors is a popular task in AI and ML. Vectors are popular because they help represent some kind of input data (like text or image) in a structured form - a set of numbers of a fixed length. This is called an embedding in ML and is actually a vector. The simplest vector is a point in a 2-dimensional space:
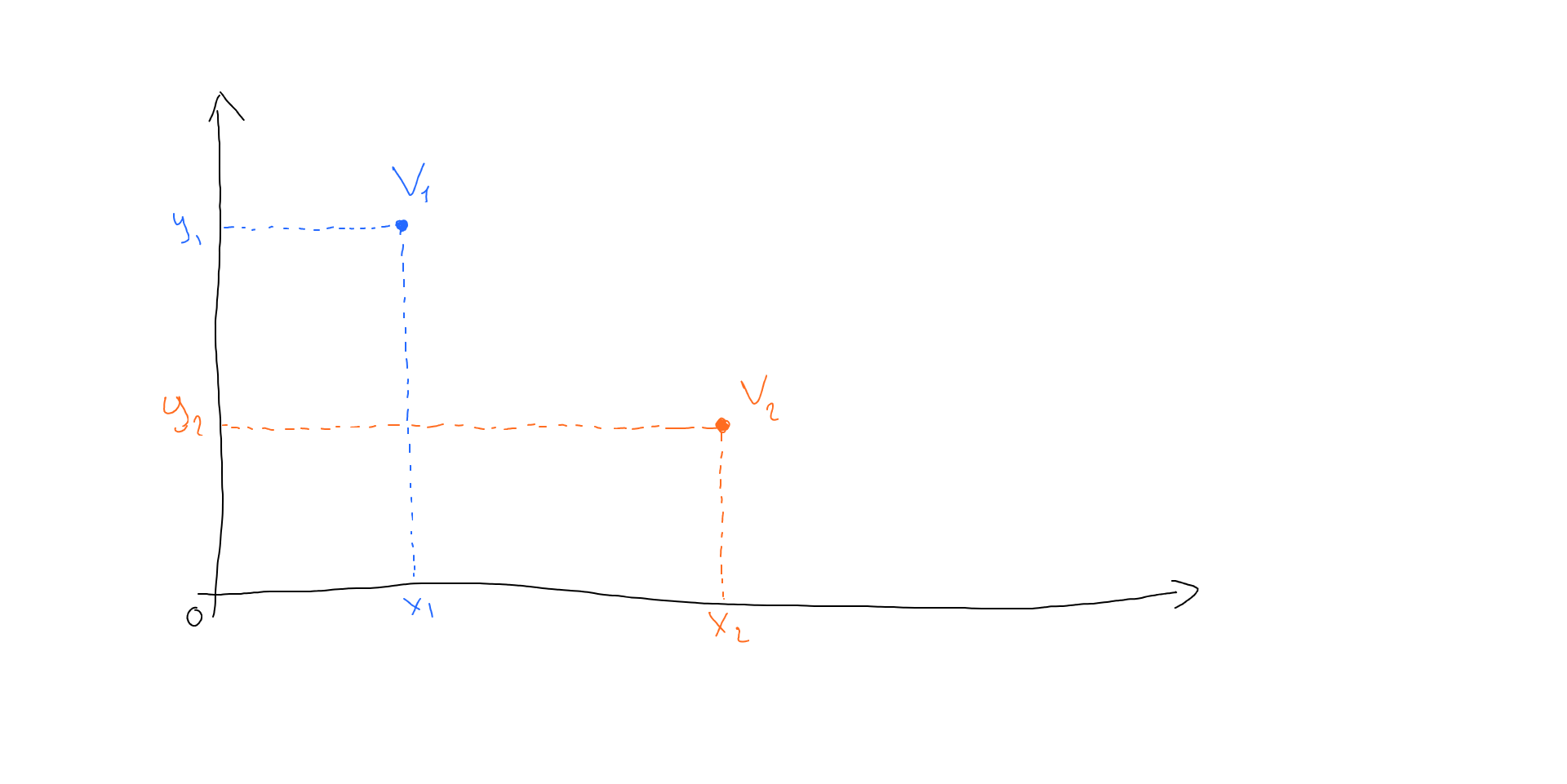
In practical tasks, vectors usually have hundreds of dimensions. An interesting feature of embeddings (vectors) is that similar objects are represented by vectors that are close to each other in space:

What we see here, is that v3 is close to v1 in space (distance d1 is small). Both vectors represent embedding for Margot Robbie’s face. While v2 (Emma Stone) is far from v1 (d2 distance is much bigger than d1). In other words, we can say that v1 and v3 vectors represent the same person, while v2 is someone else.
This is exactly how face search works. First of all, we have a database with faces and generated embeddings (vectors) for them. Then, when we have a new photo and need to find who’s that, we build embedding for this new photo and search for vectors in our database that are close to this new embedding.
To find a distance between vectors, two most common functions are used: 
While Euclidean distance is an actual distance in space between two points, cosine similarity is based on the angle between two vectors.
Why vector similarity search is slow
Let’s say we have a database of 100 million vectors (let it be 100 million faces). When we need to search for the closest vector to the one provided, we have to calculate the distance between our vector and every single vector in the database:
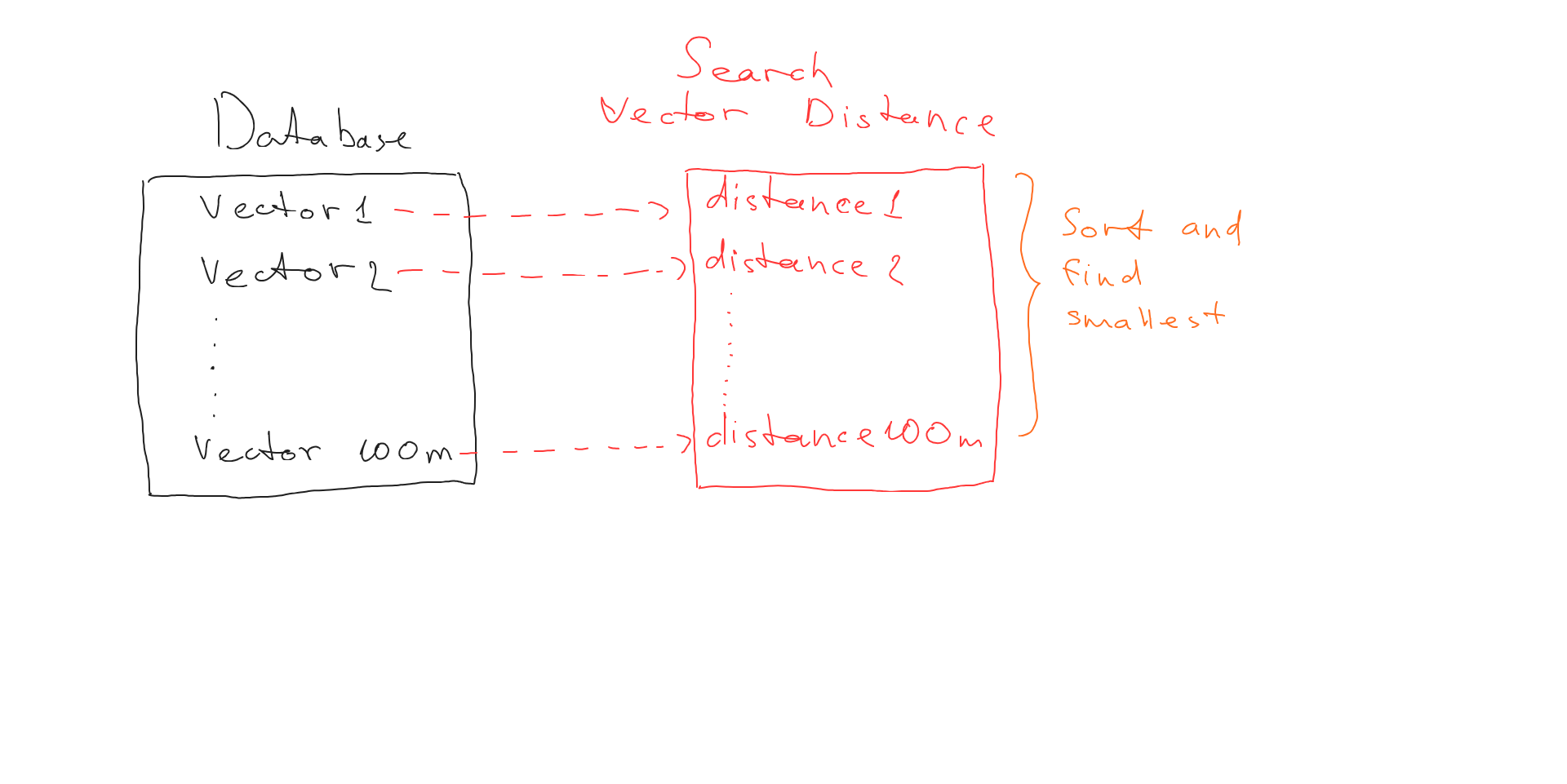
After getting all the distances (since we have 100m vectors in DB, we get 100m distances) we can now find the smallest distance and understand what vector is the nearest one. In production environments, this is slow, even for fast databases. But luckily smart people came up with strategies to make things faster.
ANN strategy for fast vector search
ANN is a way to increase similar vector search performance by reducing the number of distance calculations and locating areas instead. Let’s split the entire vector space into 2 areas:
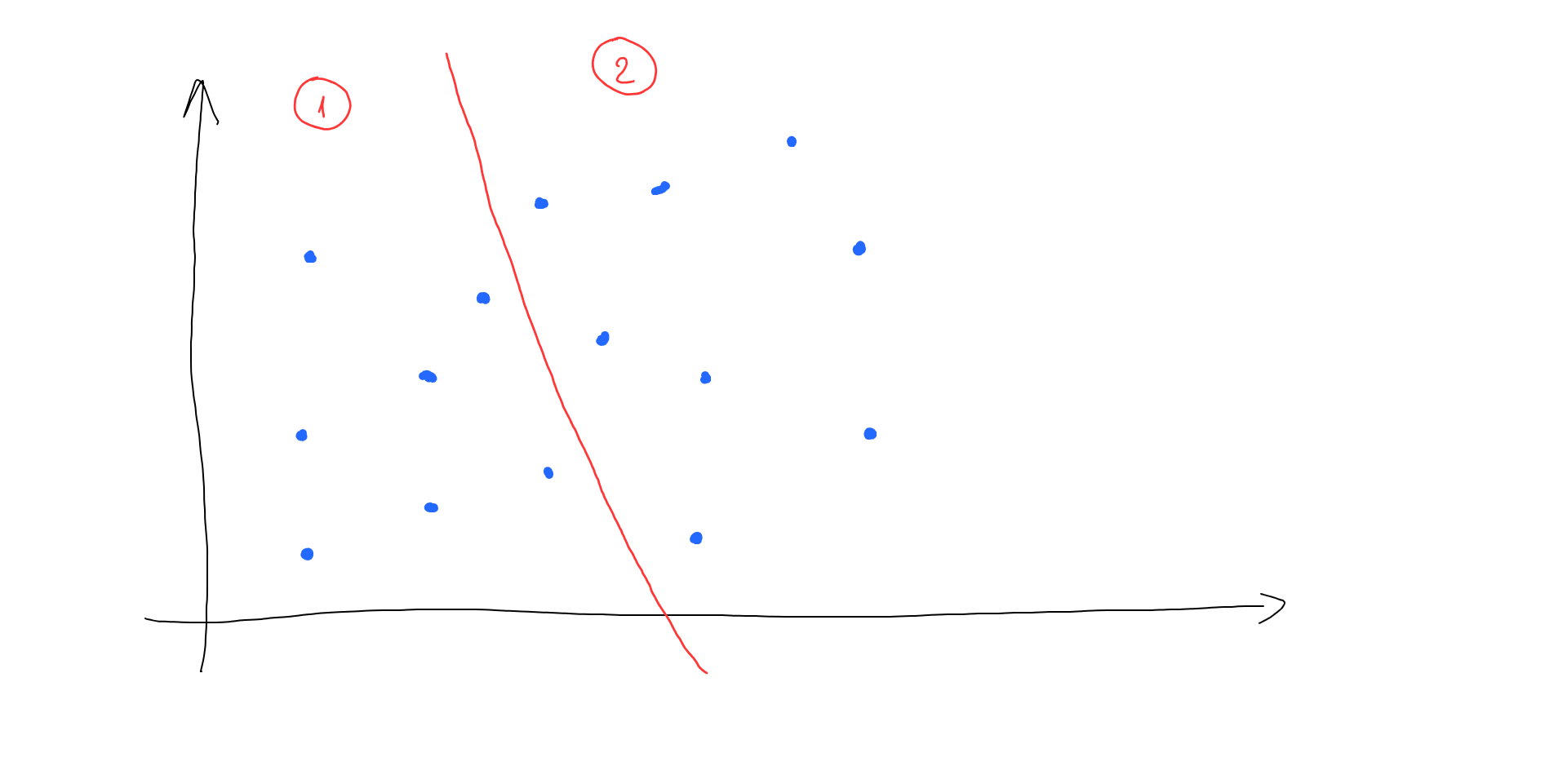
Now, when we have to locate the nearest vector to our search vector, we do not have to find all the distances. Instead, we locate which area our search vector is in, and then we only have to calculate distances with half of the vectors from our database:
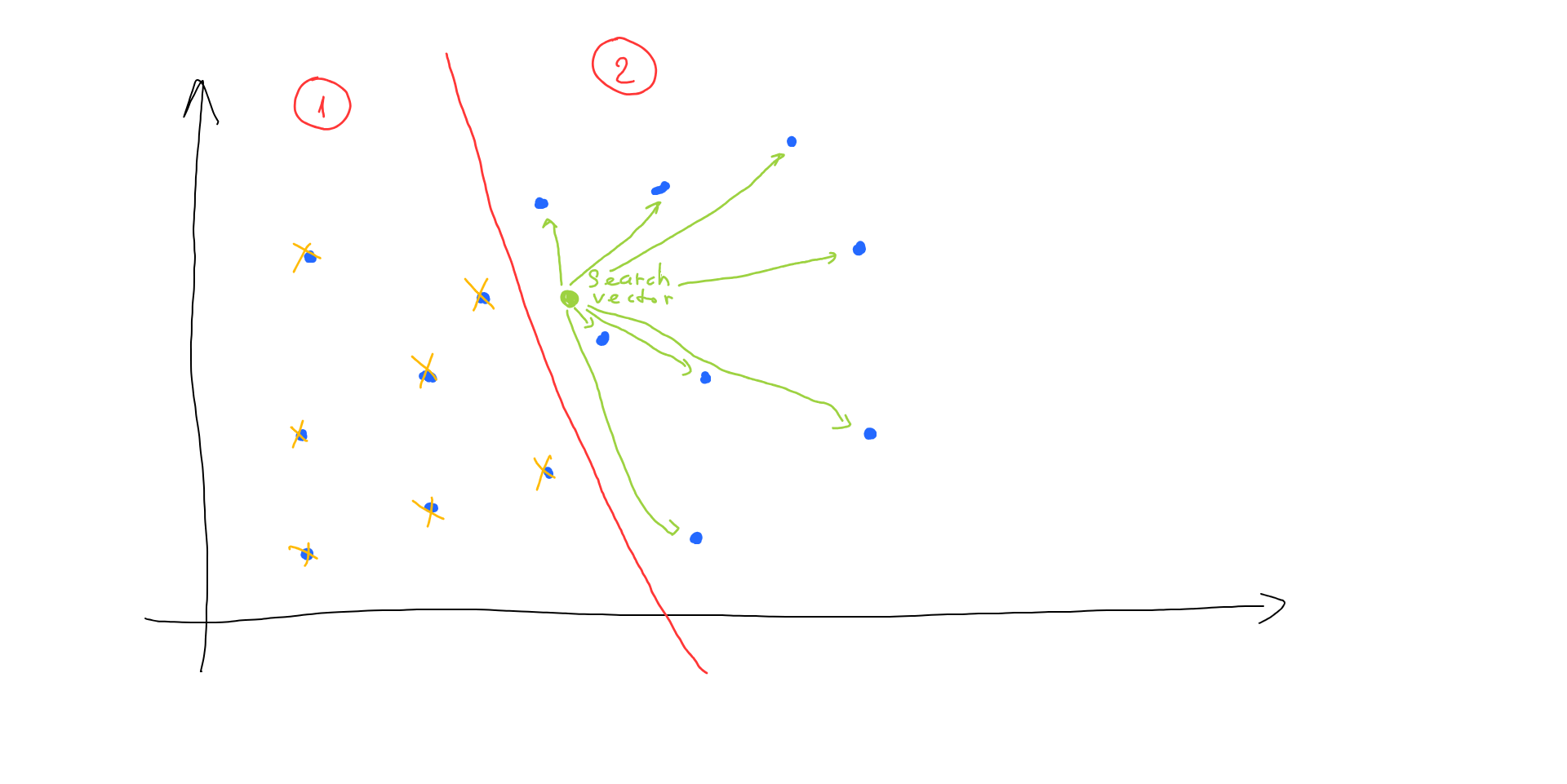
This simple approach helped us reduce the amount of distance calculation by 2 times. But what if we continue splitting our initial vector space and stop when each area has no more than, let’s say, 3 vectors in it:
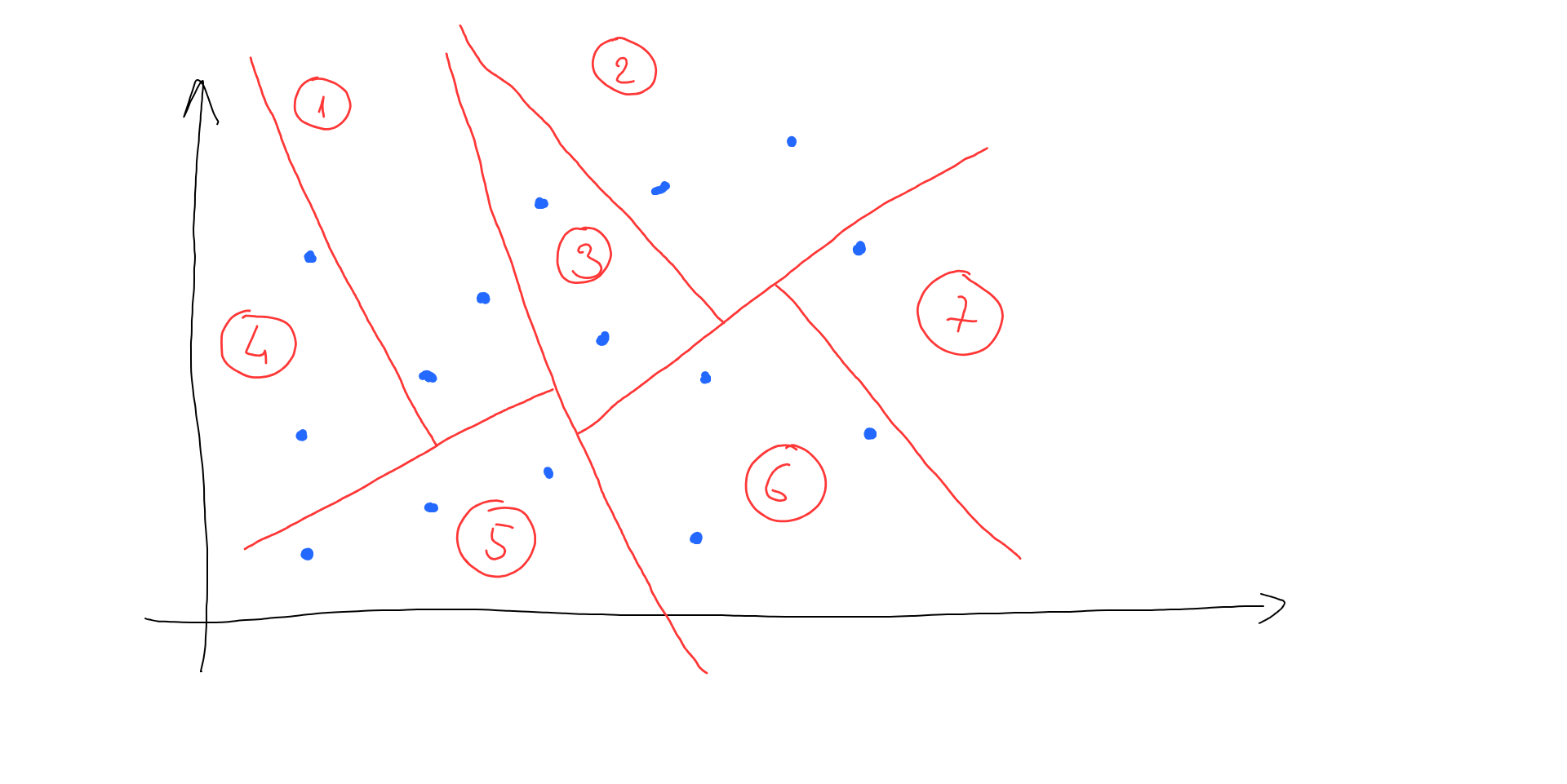
Now, instead of calculating all the distances, we can navigate through our split space areas till we find which area our search vector fits in. And only calculate distances between vectors in that area to find the nearest one:
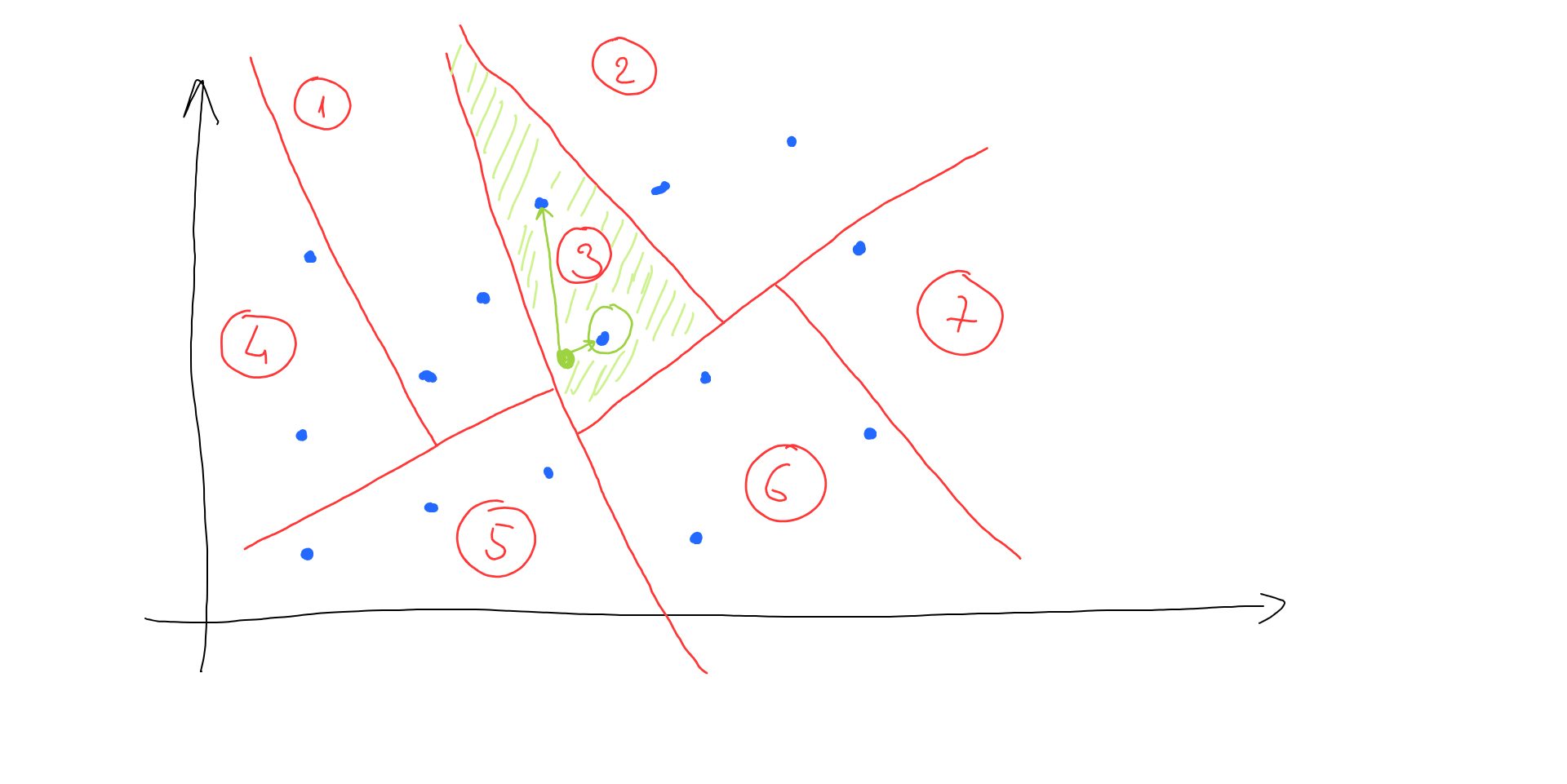
As we can see, after the target area is located, we have to calculate the distance with only 2 vectors (instead of 15 originally).
Trees in ANN
The procedure of locating the needed area looks exactly like going through a tree:
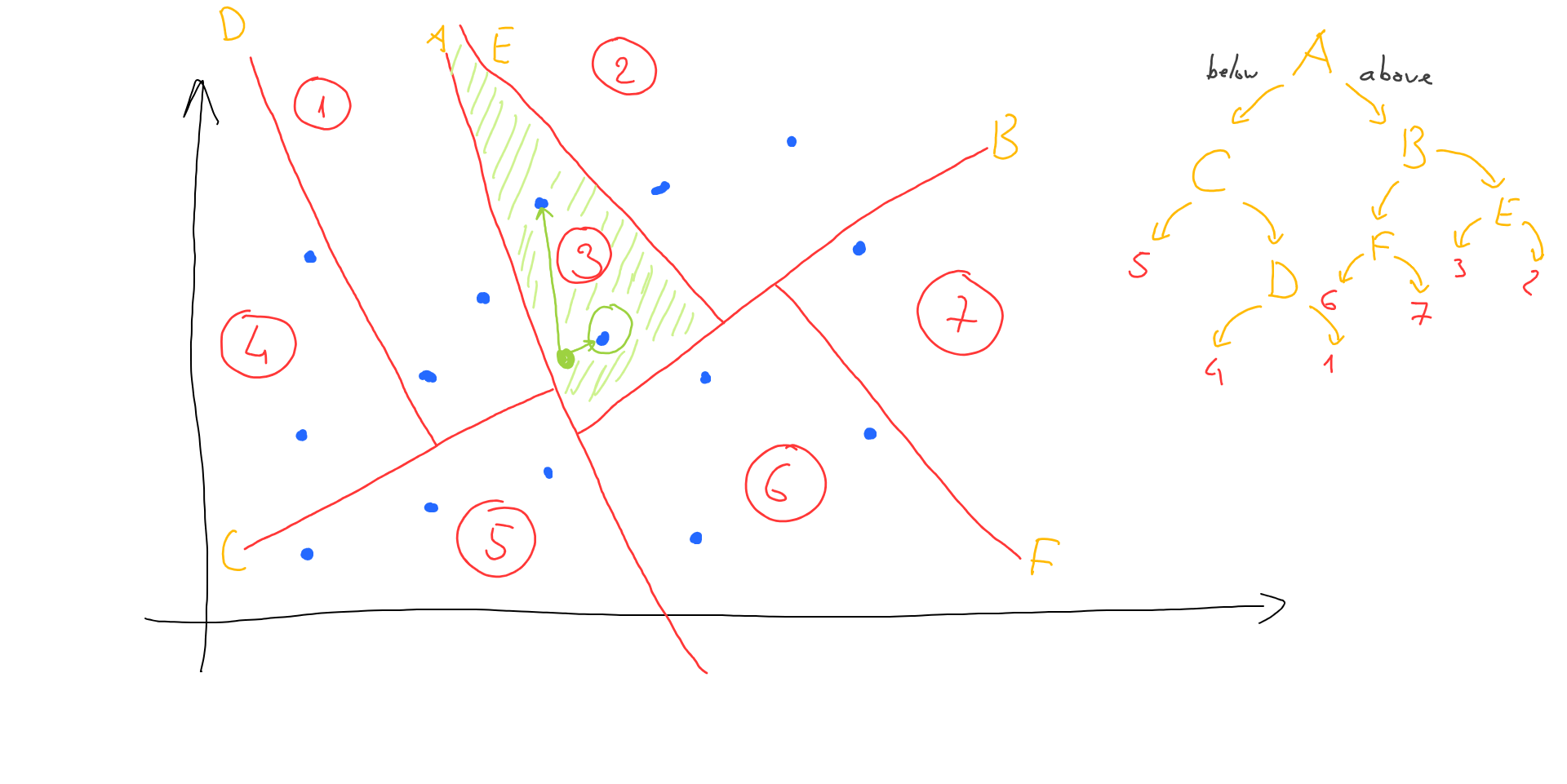
So we pick the first line to split our space (line A) and find out if our search vector is below or above this line. Then do the same for other lines (lines B and E in our case) till we end up with the final area (area 3). This process is quite fast since we go down a simple tree checking the simple above/below rule.
Approximation issues
As you can see, we can end up in a situation where ANN will return not exactly the right answer, but an approximate one. Let’s look at the following case:
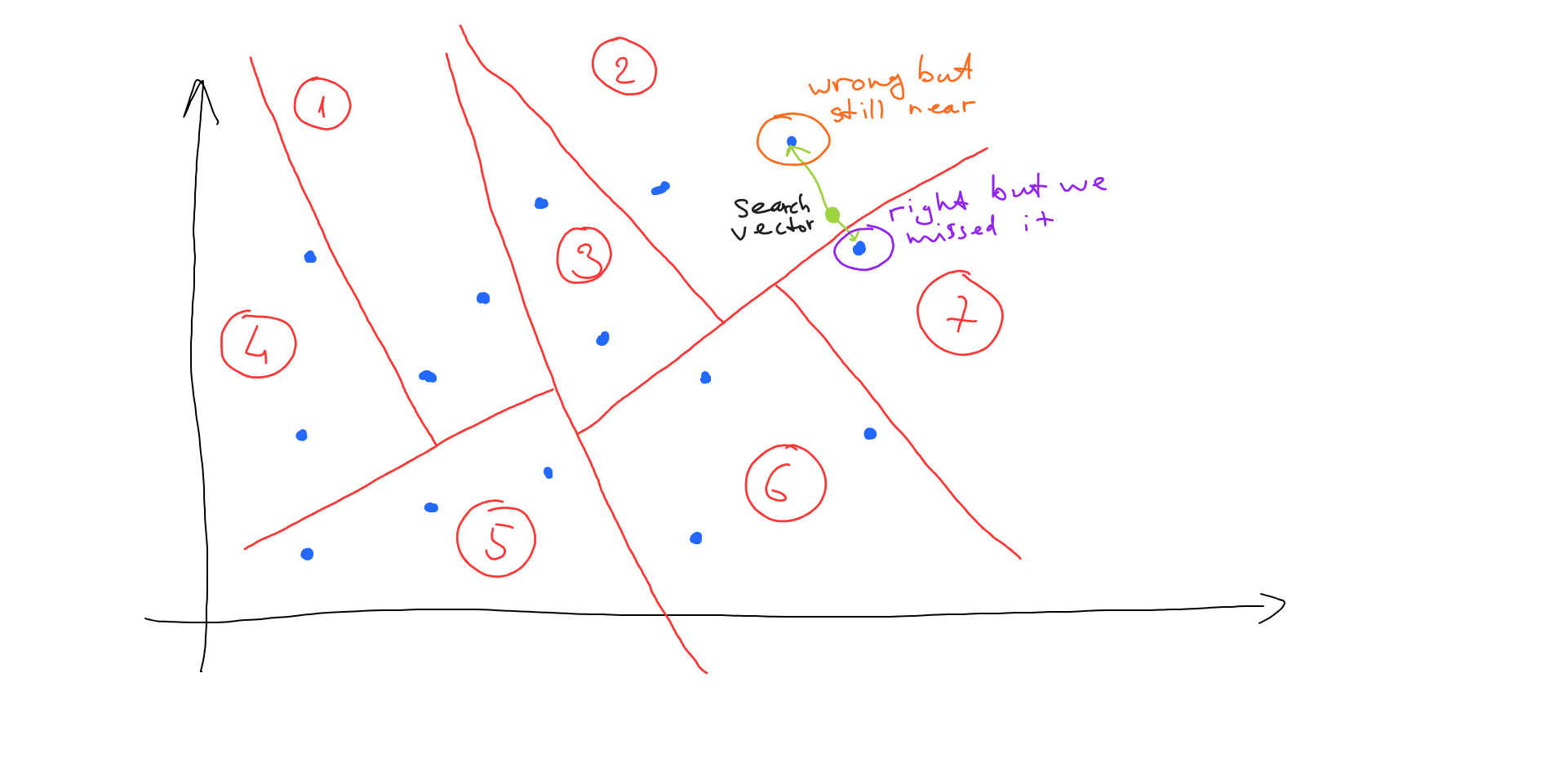
In this case, we locate area 2 and end up finding the wrong vector (it is not the nearest one from the entire vector space). Still, we’ve found a vector which is near our search vector, which can be ok for some situations in production. Another approach here is to build multiple trees (split space randomly to get different trees) and check multiple trees during the search phase:
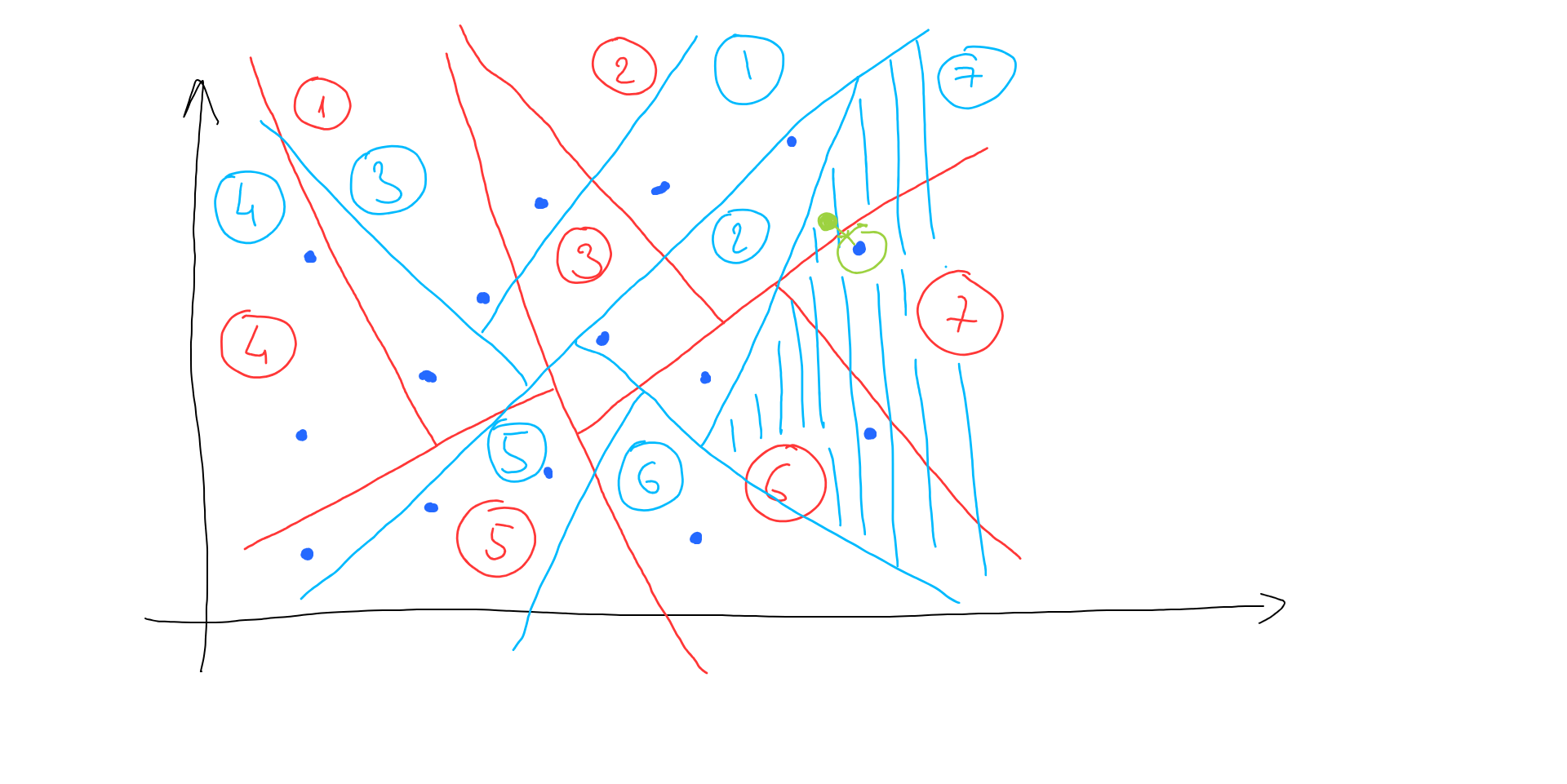
In this case, we can pick the best result from multiple trees (the blue tree will return the correct result), but the whole process will take a longer time (still much less than the entire vector space distance scan).
Using Annoy Python lib for ANN search
Cool ANN implementation is an Annoy library from Spotify. It has Python bindings included:
pip install annoyThe process of working with Annoy consists of 2 logical steps. First, we need to build an ANN index for our existing vectors. Second - search our index for the nearest vector(s) to the given one.
Generating index
from annoy import AnnoyIndex
import random
t = AnnoyIndex(32, 'angular')
for i in range(1000000):
v = [random.gauss(0, 1) for z in range(32)]
t.add_item(i, v)
t.build(10)
t.save('index.ann')246M test.annt = AnnoyIndex(32, 'angular')— creates annoy index for 32-dimensions vector search[random.gauss(0, 1) for z in range(32)]— generate random 32-dimensions vector based on gaussian-distribution randomt.add_item(i, v)— adds vector to index (wherevis the vector itself, andiis its index, which will be returned during search)t.build(10)— build ANN index using 10 treest.save('index.ann')— save ANN index to file
Here, we have created 1 million random 32-dimension vectors, generated an index using 10 trees, and saved it to the index.ann file (which takes 246Mb on disk).
Search in index
Now we can load the index and search for nearest vectors to our search vector:
from annoy import AnnoyIndex
import random
import time
u = AnnoyIndex(32, 'angular')
u.load('index.ann')
start = time.time()
search = [random.gauss(0, 1) for z in range(32)]
print(u.get_nns_by_vector(search, 5))
print('Done in ', time.time() - start, 'sec')[813387, 660630, 266190, 620721, 170101]
Done in 0.0005199909210205078 secu.load('index.ann')— loads ANN index from file (created during the previous step)search =— generate random search vectoru.get_nns_by_vector(search, 5)— find 5 nearest vectors to the given onetime.time() - start— track time it took to find similar vectors
As we can see the performance is fantastic, it takes a fraction of a millisecond to find the nearest vectors among a million.
Takeaways
ANN is a good approach to get a fast vector similarity search instead of a full scan approach. While ANN is an approximate search solution, we can still get good enough results by tuning the number of trees. One of the most efficient ANN implementations is Annoy library from Spotify with Python bindings included.
Published 2 years ago in #data about #vector search, #ann, #annoy and #python by Denys GolotiukEdit this article on Github