What is a text embedding and how to use it for text search
What is a text embedding?
A text embedding is a way to turn words or sentences into numbers:

This helps computers understand and work with text. It’s like translating words into a language that machines can understand (the language of numbers).
How is a text embedding generated?
Translating words into numbers is not hard. The harder task is to translate the text to numbers so that text meaning is somehow captured by the computer.
To capture word meaning we would want to use not just plain numbers but high-dimensional vectors (lists of numbers). This lets us save more information about the given text.
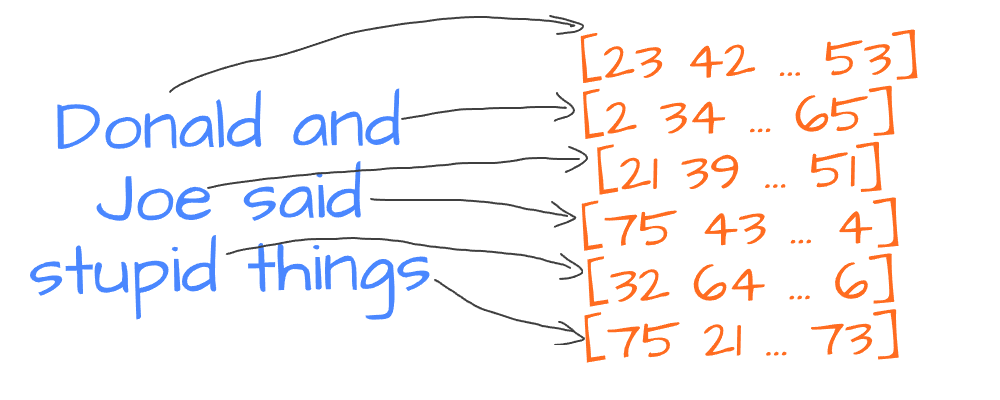
We divide our text into logical parts (words or tokens) and generate vectors for each part. To generate exact values for those vectors, we use models that have learned relationships between words from lots of text data. These models result in organizing vectors for words so that semantically similar words are placed together in the vector space:

To get a single vector from multiple words, we use special vector combining techniques. At the simplest level - we can average all word vectors to get a single vector for the entire sentence:
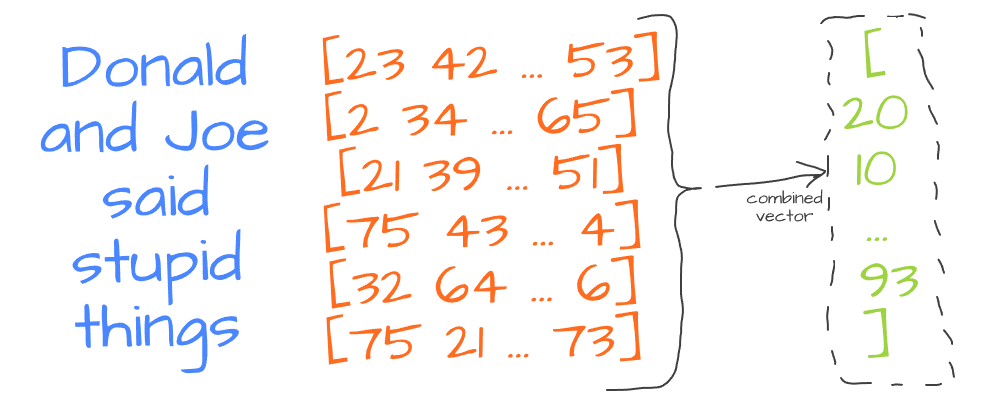
This vector captures the meaning of the text in a way that computers can use for tasks like searching or understanding text.
Getting text embeddings using OpenAI
There are a lot of embedding models currently available, but let’s take OpenAI’s embedding API for ease of demonstration purposes. According to their pricing it only costs cents per 1 million tokens.
Let’s see how to generate text embedding using OpenAI API in Python:
pip install openaiMake sure you have OpenAI API key to use:
from openai import OpenAI
text = "nuclear bomb"
client = OpenAI(api_key='<KEY GOES HERE>')
vector = client.embeddings.create(input = [text], model='text-embedding-ada-002').data[0].embedding
print(len(vector))
print(vector)1536
[-0.047446676, -0.021419598, ... 0.014650746, -0.010470366]text = "nuclear bomb"— example text to generate an embedding for,client = OpenAI— initialize OpenAI client,client.embeddings.create— creates and embedding for the given text using the given model,text-embedding-ada-002— the model we’ve chosen to generate embeddings with,vector— will contain the resulting vector of1536dimensions as we see in the output.
Now, when we can generate embeddings for text, we can implement text search based on embeddings.
Searching text using embeddings
Not only semantically similar words are placed together in space, but also semantically similar phrases (and even larger pieces of text). That’s why the idea of using embeddings for text search is pretty simple. Split input text into pieces, and generate an embedding vector for each piece. Next, generate an embedding for the query phrase and find the closest vectors to the query vector from the previously generated list:
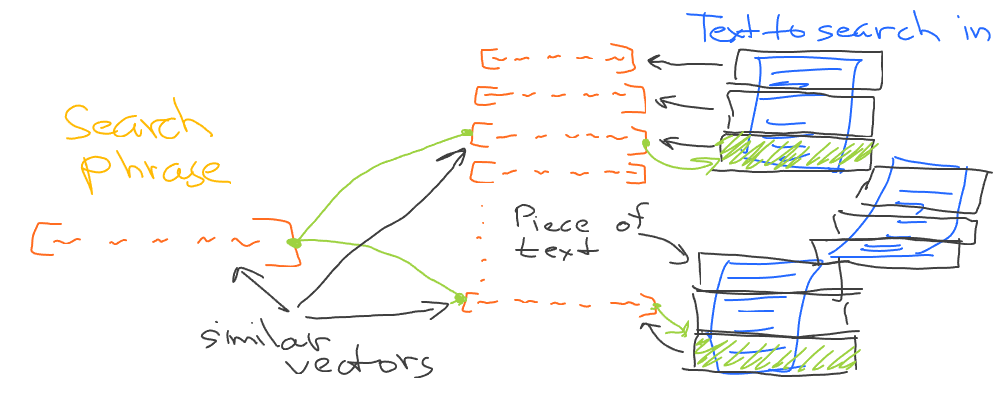
Let’s illustrate this using the history of the US article on Wikipedia.
import wikipedia
import re
wiki = wikipedia.page('History of the United States')
text = wiki.content
text = text.replace('==', '')
text = re.sub(r'\n+', '\n', text)
blocks = text.split('\n')
print(len(blocks))326import wikipedia— a handy module to work with data from Wikipedia,wikipedia.page— returns wiki object for the given page on Wikipedia (by title),wiki.content— will contain plain text representation of the article,blocks— our text pieces (text is split into blocks by newlines).
Now let’s define embed(text) function for the ease of generating a lot of embeddings using OpenAI API:
from openai import OpenAI
client = OpenAI(api_key='...')
def embed(text):
return client.embeddings.create(
input = [text],
model='text-embedding-ada-002'
).data[0].embedding
Ok. Let’s take all the text blocks and generate embeddings for them:
vectors = []
for block in blocks:
vector = embed(block)
vectors.append(vector)
print('We have', len(vectors), 'embeddings now')We have 326 embeddings nowvectors— array of embeddings,block in— iterate through each text piece,embed(block)— generates embedding for the given text piece.
Now we have the vectors array with the list of embeddings for all text pieces from the original Wikipedia article. Let’s search for the same nuclear bomb text in it:
import numpy as np
from sklearn.metrics.pairwise import cosine_similarity
query_vector = embed('nuclear bomb')
similarities = cosine_similarity(np.array(vectors), [query_vector]).flatten()
similarities = sorted(enumerate(similarities), key=lambda x: x[1], reverse=True)[0:3]
for s in similarities:
i = s[0]
print(i, ' - similarity:', s[1],':')
print(blocks[i])
print('---')199 - similarity: 0.8412414221768469 :
Military research ... atomic bombs.
The first nuclear device ever ...
they dropped atomic bombs on the Japanese
cities of Hiroshima and Nagasaki, compelling ...
Nuclear weapons have not been used...
------
191 - similarity: 0.8125609087231579 :
= World War II =
------
205 - similarity: 0.8107329494453974 :
In 1949, the United States... their first nuclear weapon test ...
the risk of nuclear warfare; the threat ...
powers from nuclear war ...query_vector— generated embedding for our query phrase,cosine_similarity— this function evaluates how similar vectors are based on the angle between them,sorted(enumerate(similarities)— we sort a list of cosine similarity values to get the most similar ones,[0:3]— pick only the first 3 most similar vectors,blocks[i]— when we know the list of most similar vectors, we can get the corresponding text piece by its index.
As we can see from the results, we’ve got 2 pretty relevant text pieces. They both got nuclear word, but not only that. In fact, the resulting texts describe nuclear/atomic weapons as a part of US history.
And a very interesting result regarding the World War II text piece (the second result). OpenAI embedding model thinks that WW2 and nuclear weapons are semantically closely related (which is a pretty correct statement). This text piece doesn’t mention nuclear weapons at all. Well, it doesn’t mention anything at all, since this is just a subtitle of the article.
In practice, we would want to split our text into blocks of the same size. This helps reduce edge cases when we compare our search query to blocks of very different sizes.
Why not just use a full-text search?
A full-text search engine will try to find the nuclear bomb phrase (and similar) in the original text. If we search for the nuclear bomb phrase in the original article, we find the following text block:

The problem here is that we have found the exact 100% phrase match, but the whole text block is completely irrelevant (which is about satellites instead of nuclear weapons). While embedding search returned a much better response in terms of semantics.
Thus, the classic search approach is good at finding exact words or phrases in the text. However, the embeddings-based search can yield much more efficient results in terms of text meaning.
Further reading
- Read more on vector similarity search in production based on ANN index,
- See how we can also find similar images based on embeddings.
Edit this article on Github