What is a language model and how it works
A language model is a computer program (or, you can say, an algorithm) that can analyze and understand human language:

Language models are used in natural language processing, speech recognition, machine translation, chatbots, and other applications.
How language models work
Ok, language models can understand human language. But how? Our machine doesn’t know anything about the meaning of sentences or words, not saying about pages of logically-related text. Letters (and other characters) are just a combination of zeros and ones for our computers. Computers just display letters on our screens for us and then we interpret them as words, sentences, and, finally, information:
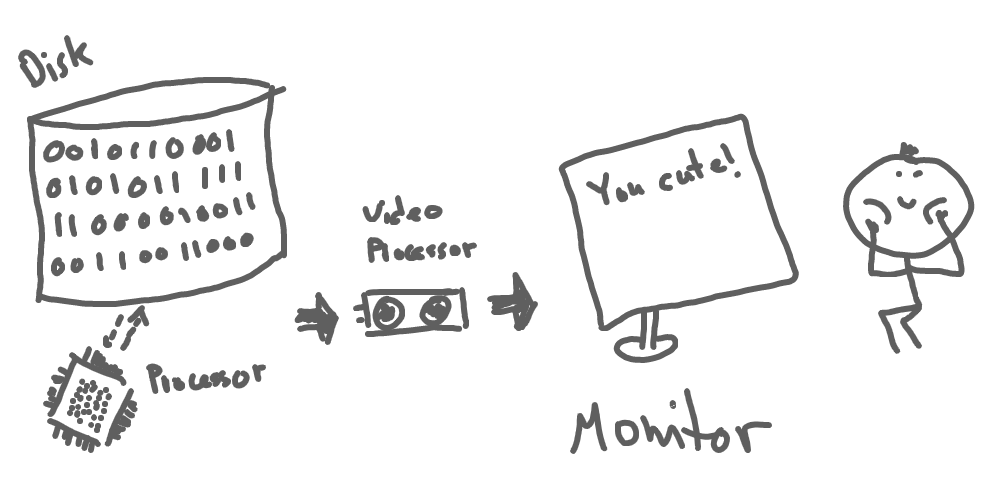
How our brain understands language?
But how do we ourselves understand language? A 1-year-old baby (like the one on the logo of Datachild) can’t talk, read and understand any verbal information. But a 5-year-old can already talk, and a 7-year-old can read and write. Our brain learns to do that by consuming a lot of verbal information.

If a child never hears anyone talk or see any text, it will not be able to learn to understand language. And this is the first important thing to note - we need input text to learn based on. And the more the better.
Now, how do we know that child understands us? We just talk to it and wait for a certain reaction, specifically a reply. If the reply makes sense to us (we understand it), this is the point when the dialog happens. This is something we want our computers to be able to do.
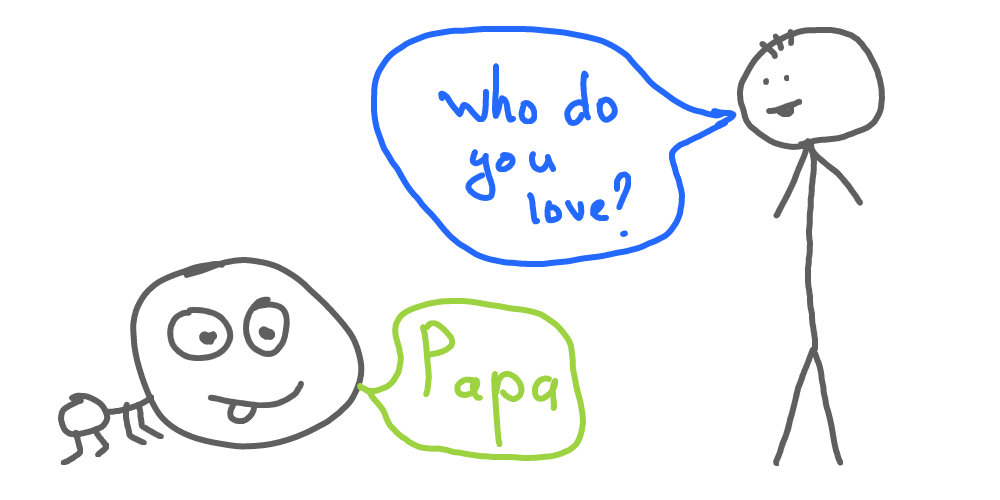
How we can teach computers to react to language
As we know, computers can predict things based on models. Let’s see how this can be used. Take the following statement (which is a sentence of 2 words):
We can create a very basic program, that will split this sentence into 2 words and then remember the first word as a possible input and the second word - as a possible output. Every time we input “good”, it will say “news”. In other cases, it will not say anything:
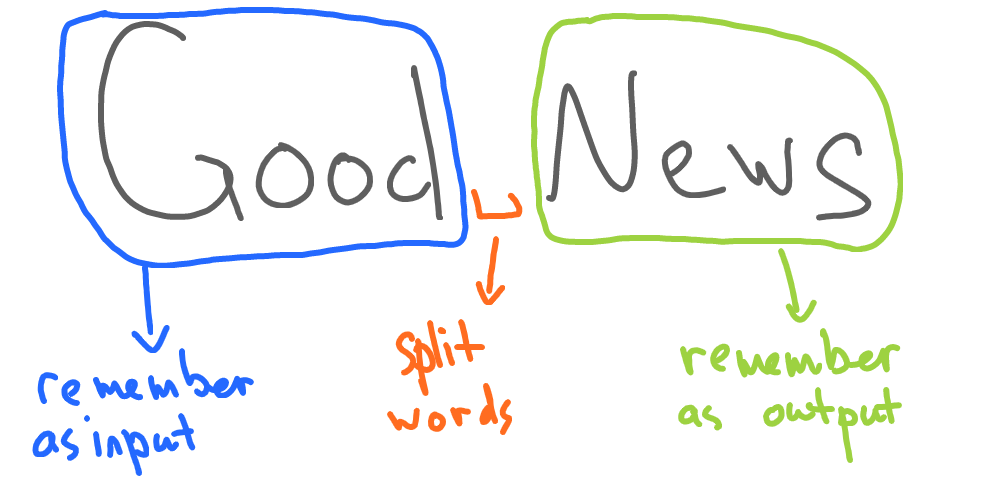
Python program might look like this:
sentence = "good news"
words = sentence.split()
answer = words[1]
question = words[0]
user_input = input("Ask me something: ")
if user_input == question:
print(answer)
else:
print("No idea what is this")python3 test.py
Ask me something: good
newssentence— the sentence we’re going to learn onsentence.split()— we split our sentence to wordsanswer— we remember last word as an answerquestion— and first word as a (possible) questioninput("Ask me something: ")— we ask the user to input some textuser_input == question— if the user has specified the question we knowprint(answer)— we print the known answerelse:— otherwise, we print that we don’t understand the user
We have built a very primitive program that has learned a single sentence of two words. It treats the first word as a possible question user can ask. And the last word as an answer. Yeah, the question is not really a question as well as the answer. It’s better to say our program can now complete a known sentence if the first part of it (first word) is provided.
But let’s change the learning sentence to this one:

And change our program a bit to skip dots and question marks:
sentence = "What is good? News."
words = sentence.replace('.', '').replace('?', '').split()
answer = words.pop()
question = " ".join(words)
user_input = input("Ask me something: ")
if user_input == question:
print(answer)
else:
print("No idea what is this")ython3 test.py
Ask me something: What is good
Newsreplace('.', '').replace('?', '')— removes dots and question markswords.pop()— remember the last word as an answer" ".join(words)— all other words are joined together into a sentence and remembered as a question
Now we have a program that can answer a single question in a single form, but it learned that by itself. If we add more sentences to learn from, it will be able to answer different questions:
sentences = [
"What is good? News.",
"Who are you? Child.",
"Are you ok? Yep."
]
knowledge = {}
for sentence in sentences:
words = sentence.replace('.', '').replace('?', '').split()
a = words.pop()
q = " ".join(words)
knowledge[q] = a
user_input = input("Ask me something: ")
if knowledge[user_input]:
print(knowledge[user_input])
else:
print("No idea what is this")python3 test.py
Ask me something: Who are you
Child
python3 test.py
Ask me something: Are you ok
Yepsentences— we now have a list of sentences to learn fromknowledge— we’re collecting pairs of questions and answers to the dictionaryknowledge[user_input]— we can now search for different questions in our knowledge base
What if we have multiple answers for the same question in our knowledge base? We can ask our program to pick the most popular (or the most probable) one.
This is a very simple example, but this is the basic idea of any language model. Our program just tries to complete (or predict and answer to, as smart people call it) user input based on its knowledge:
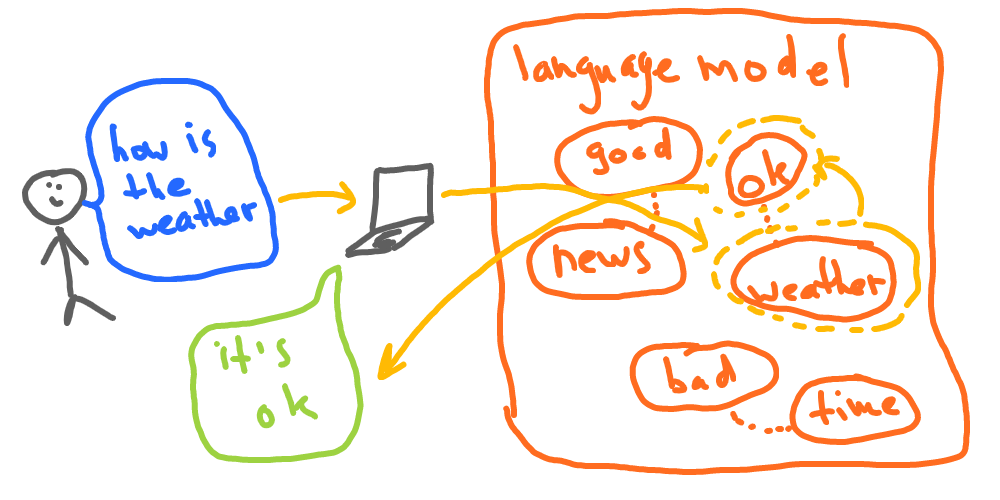
Imagine we add millions of sentences to learn from. In this case, our program would be capable of answering a lot of questions. Furthermore, we could preprocess text by removing useless words (like “a” or “and”) and parts (like punctuation). And those are still very basic improvements if we talk about modern models.
Modern language models, like ChatGPT, achieve fantastic human-like results by learning based on huge volumes of data (up to the entire internet), using a lot of text preprocessing, defining and calculating a lot of characteristics of the text (e.g., a distance between different words) and using mathematical models to predict results as opposed to simple dictionary approach we have used in our example.
Model types
There are multiple approaches to building a language model.
Rule-based models
Rule-based language models rely on handcrafted rules to parse and understand natural language. These models are typically designed by language experts.
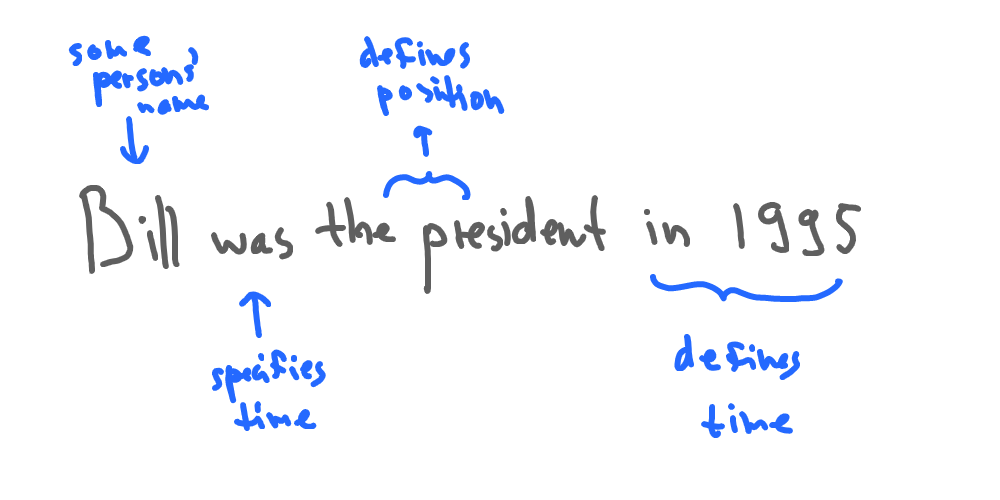
The basic idea behind rule-based language models is to define a set of rules that specify how words and phrases should be combined to form grammatically correct sentences. These rules are often based on formal grammar patterns by means of regular expressions.
Rule-based language models can be used for a wide range of natural languages processing tasks, such as part-of-speech tagging, named entity recognition, and syntactic parsing.
Statistical models
Statistical language models use statistical techniques to predict the likelihood of a sequence of words in a language (e.g. complete user input with words). These models are based on the idea that the probability of a given sentence or phrase can be estimated by analyzing the frequency of its constituent words in a large corpus of text data.
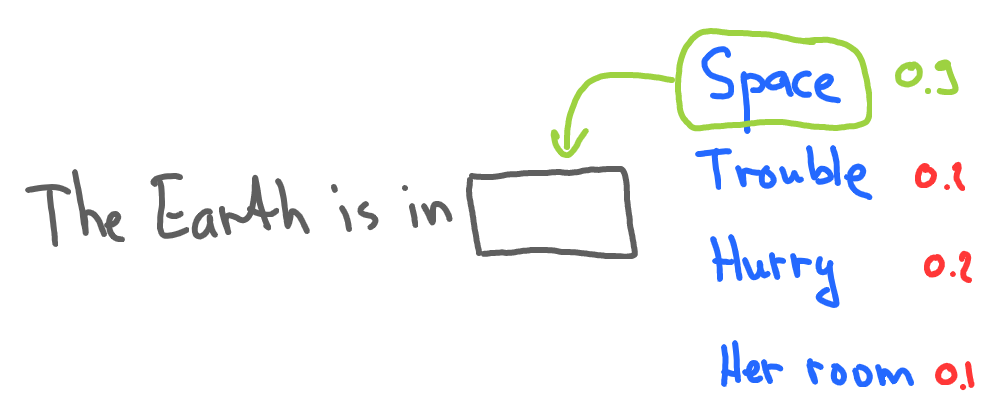
The basic idea behind statistical language models is to estimate the probability of a word given its context (e.g. previous words). For example, a statistical language model might estimate the probability of the word “space” appearing after the words “The Earth is in” based on the frequency of that sequence of words in a corpus of text data. These probabilities can then be used to generate new text or to score the likelihood of a given text.
Neural network models
Neural network language models use artificial neural networks to learn the probability distribution over sequences of words in a language. Unlike traditional statistical language models that rely on handcrafted features and models, neural network language models learn the underlying patterns and structures in the language data automatically from large amounts of text data.
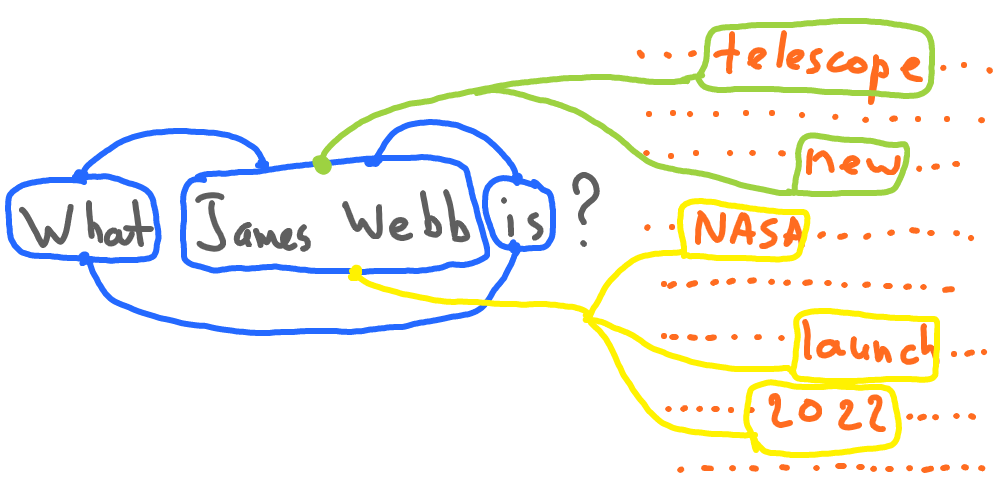
The basic idea behind neural network language models is to use a deep neural network to map a sequence of input words to a sequence of output probabilities, where each probability corresponds to the likelihood of the next word in the sequence.
Lifecycle of creating a language model
First of all, we have a lot of text available to learn from. But a text comes in many forms, languages, and structures. That’s why we need to do a lot before learning from it (or training a model, as machine learning guys would say).
Step 1 - Preprocessing
In our example, we’ve used question and answer pairs to learn based on. But what if we learn based on a text of an arbitrary form (internet articles, Wikipedia pages, comments, and so on)? Well, to handle that, modern models use text preprocessing techniques to prepare text before learning:
1. Tokenization
Tokenization is the process of splitting a sentence or a document into words or subwords. It helps to create a vocabulary of words that the language model can understand.
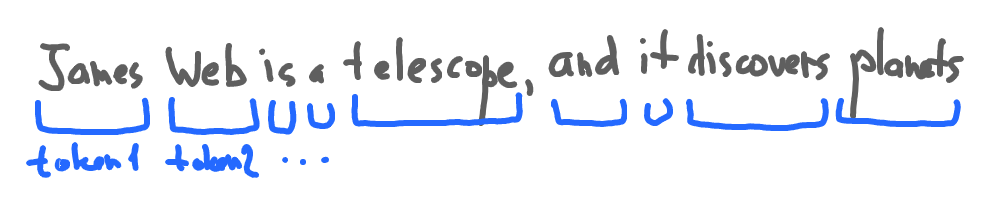
2. Stopword removal
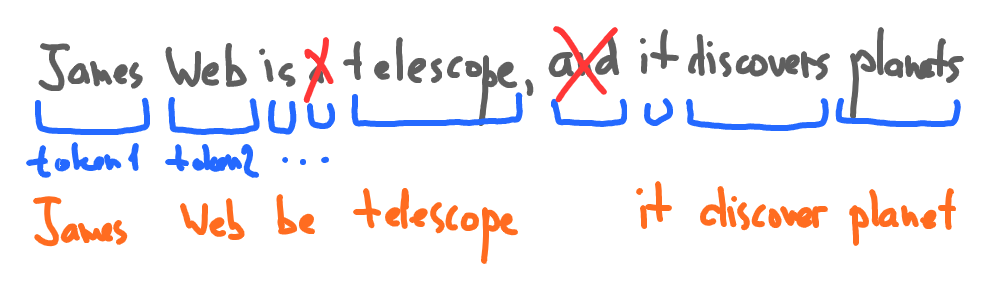
Stopwords are commonly used words such as “the,” “a,” “an,” “and,” etc., which do not add much value to the meaning of the text. Removing stopwords can help to reduce noise in the data.

3. Stemming and Lemmatization
Stemming and lemmatization are techniques used to normalize words by reducing them to their root form. This helps to reduce the number of unique words in the vocabulary and improve the efficiency of the language model.
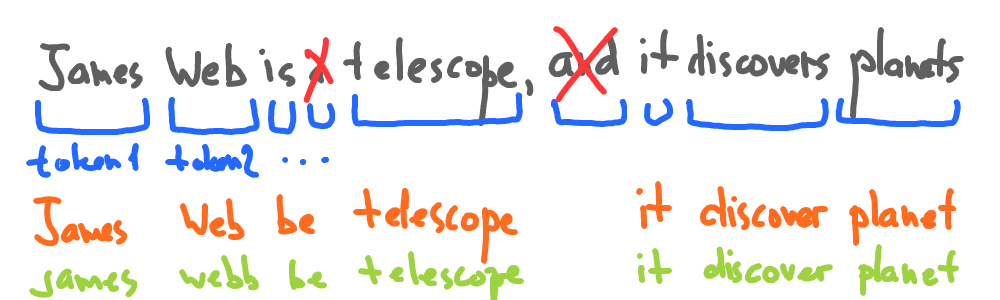
4. Spell correction, lowercasing, and removing punctuation
Converting all text to lowercase can help to reduce the size of the vocabulary and make the language model more efficient.
Punctuation marks such as commas, periods, and semicolons do not carry much meaning in the text and can be removed to reduce noise in the data.
Spell correction: Spell correction can be used to correct spelling mistakes in the text, which can improve the accuracy of the language model.
5. Encoding.
Encoding is the process of converting text data into a numerical representation that can be understood by the math language models (which are the most powerful models):
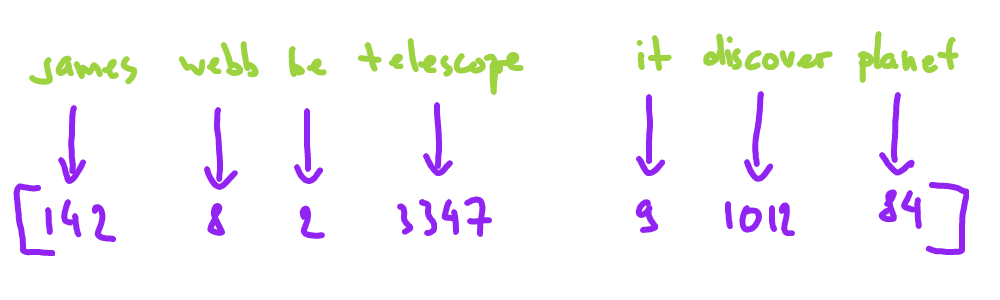
Common encoding techniques include one-hot encoding, word embedding, and BERT encoding.
Step 2 - Model training
First, we have to choose the type of neural network to use, such as a Recurrent Neural Network (RNN), a Transformer, or a Convolutional Neural Network (CNN), as well as the number of layers, the size of the hidden layers, and other architectural parameters. The next step is to choose an appropriate training algorithm, such as Stochastic Gradient Descent (SGD), Adam, or Adagrad.
Now we can actually start the training process, which involves feeding the preprocessed text data into the selected architecture and training algorithm. Then we iteratively adjust the model parameters to improve results. This process typically involves many iterations and can take hours or even months to complete, depending on the size and complexity of the model and the size of the training data.
Step 3 - Evaluation
The last stage is to understand how well our model performs. There are several metrics used for that, like perplexity or accuracy (@plan: language model evaluation metrics). The general idea here is to compare the model response with desired ones, then repeat tuning and training till metrics are good enough.
Further reading
- How to create Bigram statistical language model in Python
- (@plan: Preprocessing text data for a language model in Python)
Edit this article on Github