How to use multiple disks in Clickhouse
Clickhouse allows using different storage backends for data, including local disks and remote ones, like Amazon S3. It’s quite common to have multiple storage devices when dealing with a lot of data.
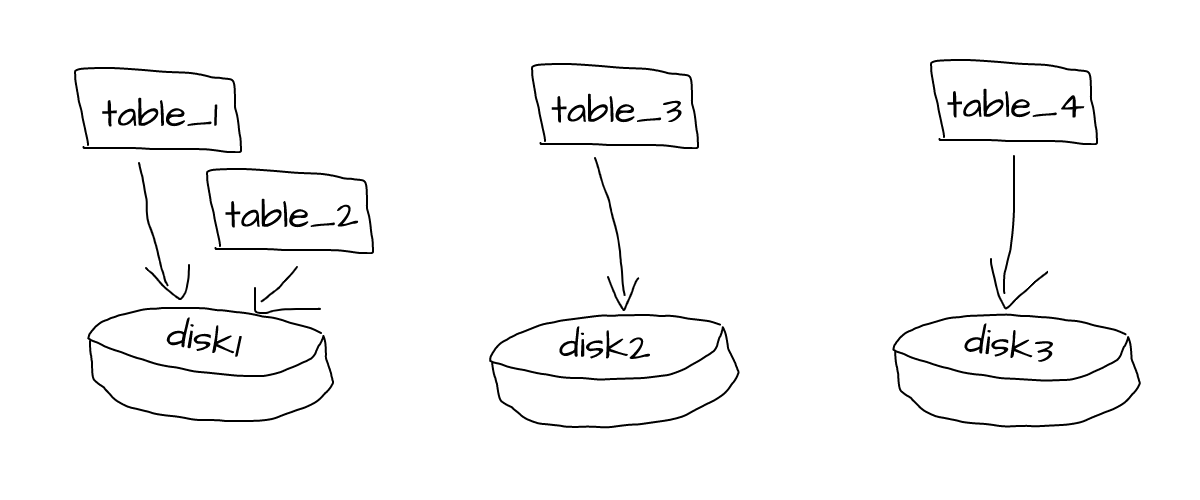
Clickhouse allows working with multiple disks on the same server, making it easy to scale beyond single storage device locally.
Configure multiple disks
First, we need to list all of our local disks in configuration, so Clickhouse knows what it can work with. Prefered way is to create new xml file under /etc/clickhouse-server/config.d directory (disks.xml in our case). Let’s say we have 3 local storage devices (disks), one default (used by the system already) and two that we want to use in Clickhouse.
Before adding disks to Clickhouse, we should create data (named clickhouse in our case) folder and grant access to clickhouse user to it:
mkdir /mnt/disk2/clickhouse
chown clickhouse:clickhouse /mnt/disk2/clickhouse
mkdir /mnt/disk3/clickhouse
chown clickhouse:clickhouse /mnt/disk3/clickhouse/mnt/disk2/clickhouse— folder to be used by Clickhouse on this disk,clickhouse:clickhouse— make sure this new folder is accessible to Clickhouse.
Now we can register our disks using the following configuration (in /etc/clickhouse-server/config.d/disks.xml file):
<clickhouse>
<storage_configuration>
<disks>
<d2><type>local</type><path>/mnt/disk2/clickhouse/</path></d2>
<d3><type>local</type><path>/mnt/disk3/clickhouse/</path></d3>
</disks>
<policies>
<d2_main><volumes><main><disk>d2</disk></main></volumes></d2_main>
<d3_main><volumes><main><disk>d3</disk></main></volumes></d3_main>
</policies>
</storage_configuration>
</clickhouse><d2>— name of the second storage device,<type>local</type>— type of device is local disk,/mnt/disk2/clickhouse/— path to by used by Clickhouse to storage data (mention the closing/used in path),<d2_main>— policy name for the second storage device, so we can use it for tables.
No need to restart Clickhouse server, since it’s gonna read configuration updates and automatically load it in background. To make sure disks are available to Clickhouse we can look at system.disks table:
SELECT * FROM system.disks\GRow 1:
──────
name: d2
path: /mnt/disk2/clickhouse/
...
Row 2:
──────
name: d3
path: /mnt/disk3/clickhouse/
...Using different disks for different tables
Now we can specify which disk we want to store our table to while creating it:
CREATE TABLE some_table ( `some_column` String, )
ENGINE = MergeTree ORDER BY uuid
SETTINGS storage_policy = 'd3_main'storage_policy— allows setting custom storage policy for the table,d3_main— in our case we want Clickhouse to put this table on disk3.
That’s it. Now Clickhouse will automatically use disk3 to write/read some_table data. Note, that Clickhouse can automatically move data between disks accordingly to “hot/cold” storage policies.
Further reading
- Using Amazon S3 to store Clickhouse data
- Using Amazon S3 to backup & restore Clickhouse
- Clickhouse storage_policy configuration
Edit this article on Github