Using Sphinx to add full-text search to Clickhouse
At the moment of writing (May 2023), Clickhouse doesn’t support full-text search indexes. Although it has ngram-based and token-based data skipping indexes, you might need an external solution for full-featured text search, like Sphinx.
Overview of a solution
So, Sphinx enables us to do full-text searches. It works by searching through previously created indexes based on data from Clickhouse:
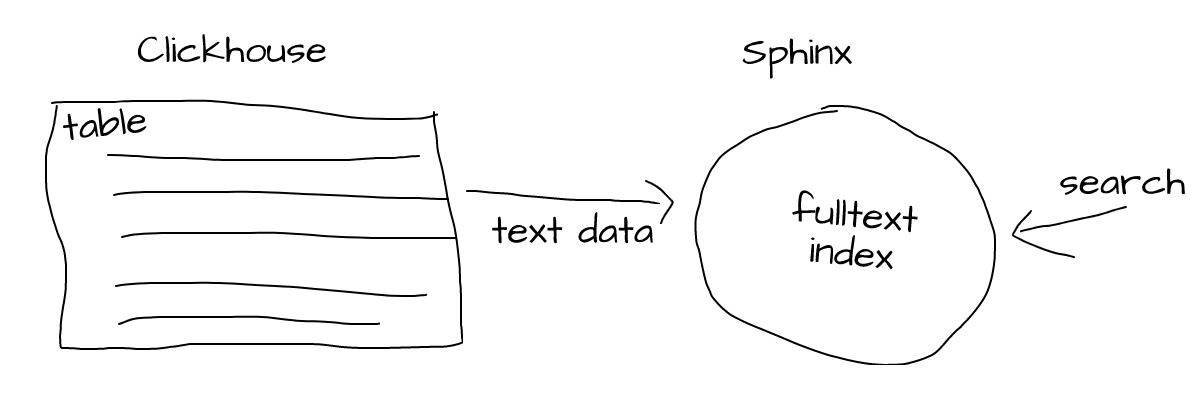
So we feed text data from Clickhouse to Sphinx and it’ll index that text data for further (efficient) search.
Typically, when we search Sphinx, it returns IDs of matched documents. We can then resolve those IDs to original documents in Clickhouse:
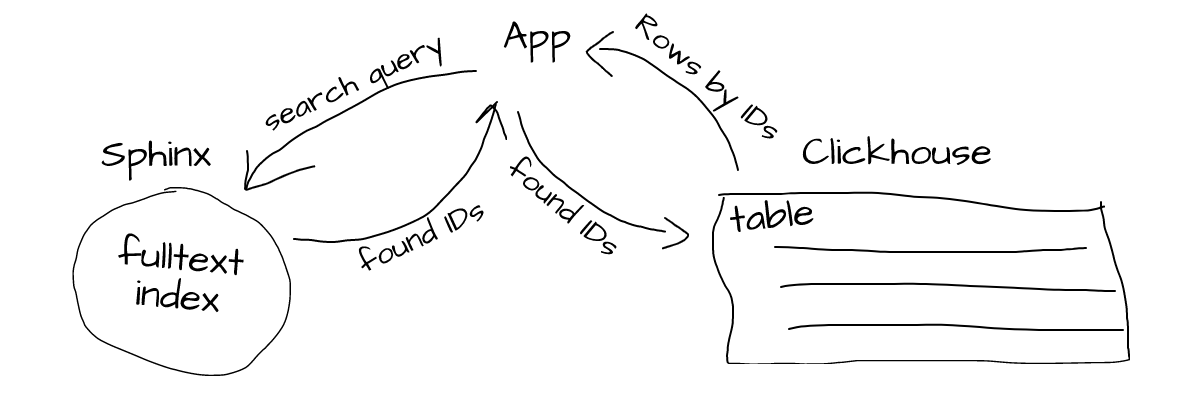
To use Sphinx with Clickhouse, we have to configure an index and run an indexing process to build a full-text index. When it’s done, we can use Sphinx to search text data from Clickhouse.
Configuring Sphinx index
Sphinx stores text data in documents (just like table rows), and each document should have a unique ID, which Sphinx requires to be a 64-bit integer. Since Clickhouse doesn’t (yet?) support autoincrement fields, we should generate a unique ID (which is an integer) for each row of our table that we want to index. ClickHouse has rowNumberInAllBlocks() function to add a row number to the result of the query:
SELECT rowNumberInAllBlocks(), col1, col2 FROM some_tablerowNumberInAllBlocks()— will add a number of a row to the result set,col1, col2— columns ofsome_tablethat we want to select.
We won’t actually use that ID later, so we only need it to surpass Sphinx requirements.
UUID to identify Clickhouse table rows
Sphinx will only store the text index, not the text itself (unless we ask it to). That’s why we need a way to identify documents in Sphinx and corresponding records in Clickhouse. In other words, we need a unique identifier for each row in our Clickhouse table. That’s exactly, what standard Sphinx document ID is supposed to be used for, but we can’t use it since we don’t have a way to generate a unique integer value for each table record in Clickhouse.
Luckily, Clickhouse has UUID type and can generate unique UUIDs using generateUUIDv4(). We can use this function as default expression for uuid column to have Clickhouse automatically generate UUIDs for each row of our table:
CREATE TABLE some_table
(
`col` String,
`uuid` UUID DEFAULT generateUUIDv4()
)
ENGINE = MergeTree ORDER BY ()uuid— this column will have a unique UUID for each record,DEFAULT— this allows specifying expression to use if the column is omitted during data insert.
Now we can ask Sphinx to save the uuid column value during indexing and return it when searching.
Sphinx index configuration
We can use tsvpipe as a way to feed text data from Clickhouse to Sphinx. Let’s configure our index (usually appended to the /etc/sphinx/sphinx.conf file):
source txt_src
{
type = tsvpipe
tsvpipe_command = clickhouse-client -q "SELECT rowNumberInAllBlocks() + 1, col, uuid FROM some_table FORMAT TSV"
tsvpipe_field = col
tsvpipe_attr_string = uuid
}
index txt
{
source = txt_src
path = /var/indexes/txt
}type = tsvpipe— source type to readTSVdata,tsvpipe_command— the result of this command should beTSVdata to index,- ‘+ 1’ - we use it to start document IDs from
1instead of0, tsvpipe_field = col— indexcolcolumn as text,tsvpipe_attr_string = uuid— Sphinx will return theuuidvalue when searching so we can use it later,index txt— the name of our index istxt.
Building and searching an index
Now we can ask Sphinx to index data:
indexer txt --rotateindexer— Sphinx indexer utility,txt— the name of our index (defined previously in config),--rotate— will ask the running Sphinx process to use the new index once it’s ready.
At this point, we’re able to query Sphinx:
mysql -P 9306 -h 127.0.0.1 -e "select uuid from txt where match('test')"+--------------------------------------+
| uuid |
+--------------------------------------+
| 83c05036-0490-4ee4-b7aa-9554deaa564d |
...
| cfb234d9-18da-496f-adc4-354aaf54c747 |
+--------------------------------------+mysql— we use a Mysql client since Sphinx understands Mysql protocol,-P 9306— default Sphinx port for Mysql protocol,select uuid from txt— we ask Sphinx to retrieve only theuuidattribute from thetxtindex,match('test')— search for thetestword in indexed documents.
Resolving documents
After we got uuid values from Sphinx, we can look them up in Clickhouse:
SELECT col FROM some_table WHERE uuid IN ('83c05036-0490-4ee4-b7aa-9554deaa564d', ...)┌─col───────────────────────────────────────────────────┐
│ test text 1901-01-01 words 119602 test - test, 22,33 │
...
└───────────────────────────────────────────────────────┘uuid IN— we filter theuuidcolumn based on values returned from Sphinx.
It’s important to mention, that Clickhouse uuid lookup performance will dramatically depend on a table sorting key.
Further reading
- (@Plan: Optimizing Clickhouse full-text search with Sphinx attributes)
- Ngram Bloom filter in Clickhouse
- Token Blook filter in Clickhouse
- CSV/TSV index source in Sphinx
Edit this article on Github