How to merge large tables in ClickHouse using join
One case that needs attention in ClickHouse is when we need to merge data from different tables horizontally using a join on a certain key column. Suppose, we have two tables - events and errors. Both of them have the event_id key and we would like to join them to the resulting table with all columns from both source tables:

OvercommitTracker problem
Wait, why can’t we just join those on the fly?
SELECT count(*)
FROM events e JOIN errors r
ON (r.event_id = e.event_id)
WHERE label = 'payment' and error = 'out-of-money'events e JOIN errors r— join two tables,r.event_id = e.event_id— column to join on.
Well, yes, but joining large tables can lead to consuming a lot of memory, and the following error might occur:
Code: 241. DB::Exception: Received from localhost:9000.
DB::Exception: Memory limit (total) exceeded:
would use 8.39 GiB (attempt to allocate chunk of 2147614720 bytes),
maximum: 6.99 GiB. OvercommitTracker decision:
Query was selected to stop by OvercommitTracker.: While executing JoiningTransform. (MEMORY_LIMIT_EXCEEDED) (query: ...)MEMORY_LIMIT_EXCEEDED— not enough memory to join big tables.
This happens, because ClickHouse has OvercommitTracker that decides to stop further execution of the query that’s trying to use more memory than we have (can be also configured).
Joining large tables by parts
Since we usually deal with large tables in ClickHouse, we might meet that error once in a while.
A practical approach to this problem is to do several smaller joins instead of the single big one:
- Define a total range (min and max values) of the key column (the one we join on,
event_idin our case). - Split that range into multiple parts, so we can join separate parts instead of entire tables. The number of parts should be picked so that there’s enough RAM to execute join for each individual part (so might vary from tens to hundreds or even thousands).
- Iterate through all parts to build the resulting table.
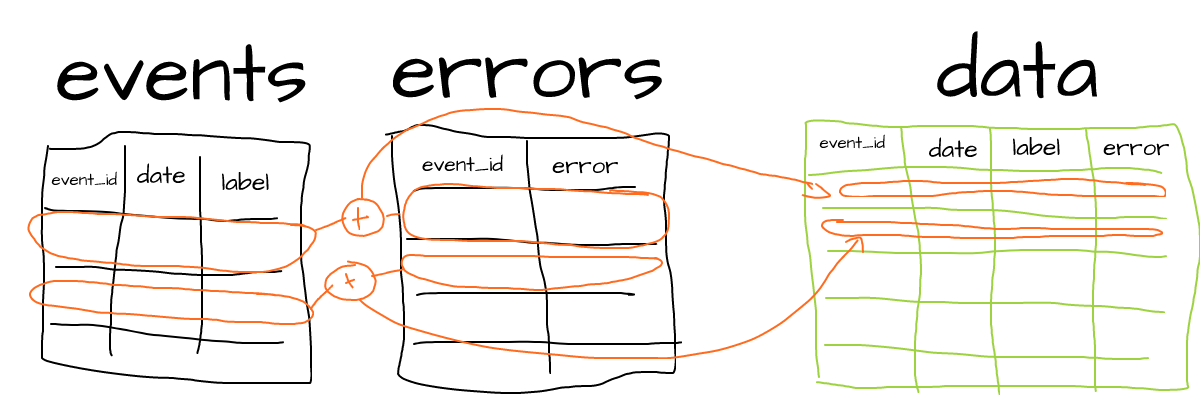
Example PHP code to join our tables by parts:
$table_left = 'events';
$table_right = 'errors';
$bulk = 1000000;
$min_max = clickhousy::row('SELECT min(id) min, max(id) max FROM ' . $table_left);
$offset = $min_max['min'];
$max = $min_max['max'];
do {
$limit = $offset + $bulk;
$sql = "INSERT INTO data " .
"SELECT event_id, date, label, error FROM ".
"(SELECT * FROM {$table_left} WHERE event_id >= {$offset} and event_id < {$limit}) as t1 " .
"LEFT JOIN (SELECT * FROM {$table_right} WHERE event_id >= {$offset} and event_id < {$limit}) as t2 " .
"ON (t1.event_id = t2.event_id)";
echo "{$offset}
";
passthru('clickhouse-client --progress -q ' . escapeshellarg($sql));
$offset = $limit;
} while ( $offset < $max );$table_left— source table,$table_right— table to join,$bulk— step inevent_idvalue increase over iterations (1 million in our case),clickhousy::row— gets a single record from ClickHouse clickhousy lib,INSERT INTO data— we insert data into the resultingdatatable,event_id >=andevent_id <— select only a limited range of records from both tables using theevent_idcolumn,ON (t1.event_id = t2.event_id)— join filtered parts instead of entire source tables,$offset < $max— iterate while we meet maxevent_id.
Things to note
First of all, mind efficiency of filtering queries. It’s good if event_id can be used as an index. If it’s not, filtering might take a lot of time. Consider using columns that can leverage sorting key.
We assumed our event_id column is numeric and its values are distributed more or less sequentially. But in practice, we might have uuid, other types, or even multiple columns to join on. In this case, consider using a preliminary query with ORDER BY and LIMIT OFFSET to get filtering ranges:
SELECT col1 FROM source_table ORDER BY col1 LIMIT 1000000, 1col1— column to join on,ORDER BY col1— sort values,LIMIT 1000000, 1— offset by the number of rows we want to process in a single iteration (this should be executed for each iteration with respective offset).
Further reading
- JOIN in ClickHouse
- Query execution resources limits in ClickHouse
- ClickHouse primary keys and query performance
Edit this article on Github